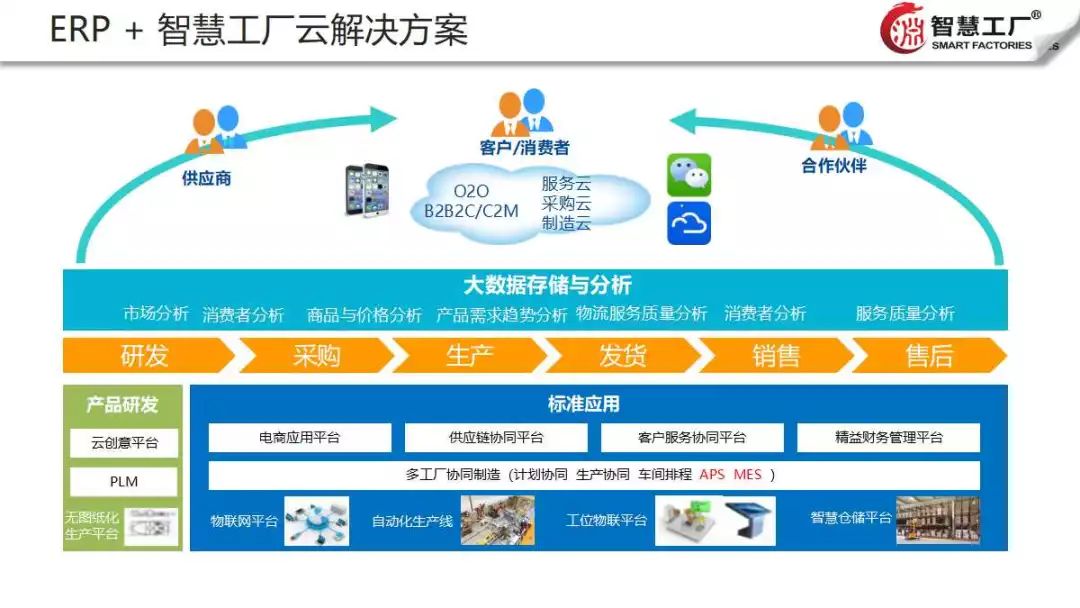
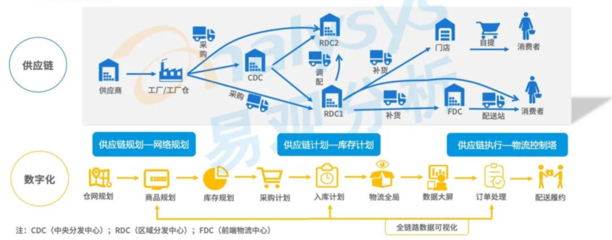
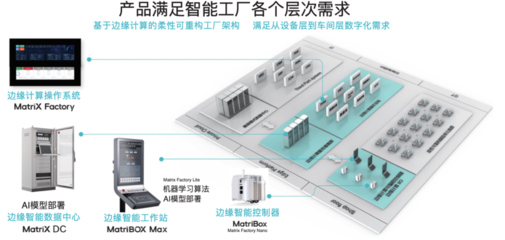
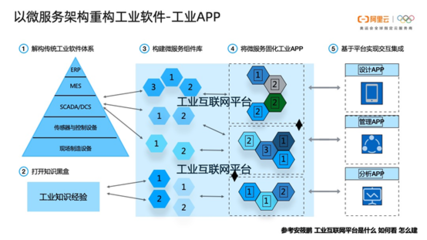
构建集团企业多工厂MES数据处理和存储服务的策略与方法
随着制造业向智能化、数字化方向发展,制造执行系统(MES)在集团企业中扮演着关键角色,特别是在多工厂运营场景中。MES负责收集、处理和存储生产过程中的实时数据,为决策提供支持。多工厂环境下,数据分散、异构系统集成复杂、数据安全要求高等挑战使得构建高效的MES数据处理和存储服务成为一项关键任务。本文将探讨如何构建集团企业多工厂MES的数据处理和存储服务,涵盖设计原则、架构方案和实施策略。
一、明确业务需求与挑战分析
在构建多工厂MES数据处理和存储服务前,首先要明确业务需求,例如实时监控、生产追溯、效率分析等。需识别多工厂环境下的特有挑战:
- 数据异构性:不同工厂可能使用不同的设备、系统和数据格式,导致数据标准化困难。
- 高并发与实时性:多工厂同时产生海量数据,要求系统能高效处理和存储,支持实时查询。
- 数据安全与合规:集团企业需确保数据隐私和工业安全,遵守相关法规。
- 可扩展性:随着工厂数量增加,系统应能灵活扩展,避免性能瓶颈。
二、设计数据处理和存储服务的核心原则
为应对上述挑战,设计时应遵循以下原则:
- 统一数据标准:制定集团级数据模型,确保各工厂数据格式一致,便于整合和分析。
- 分布式架构:采用分布式系统设计,实现负载均衡和容错能力,提高系统可靠性。
- 模块化与松耦合:将数据处理、存储和服务模块分离,便于维护和升级,支持工厂独立部署。
- 实时与批处理结合:结合流处理(如Apache Kafka或Flink)和批处理(如Hadoop或Spark),实现数据实时分析和历史数据挖掘。
- 安全优先:实施加密、访问控制和审计机制,确保数据在传输和存储中的安全性。
三、构建数据处理和存储服务的架构方案
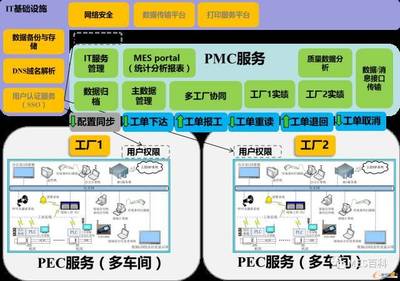
一个典型的多工厂MES数据处理和存储架构可包括以下组件:
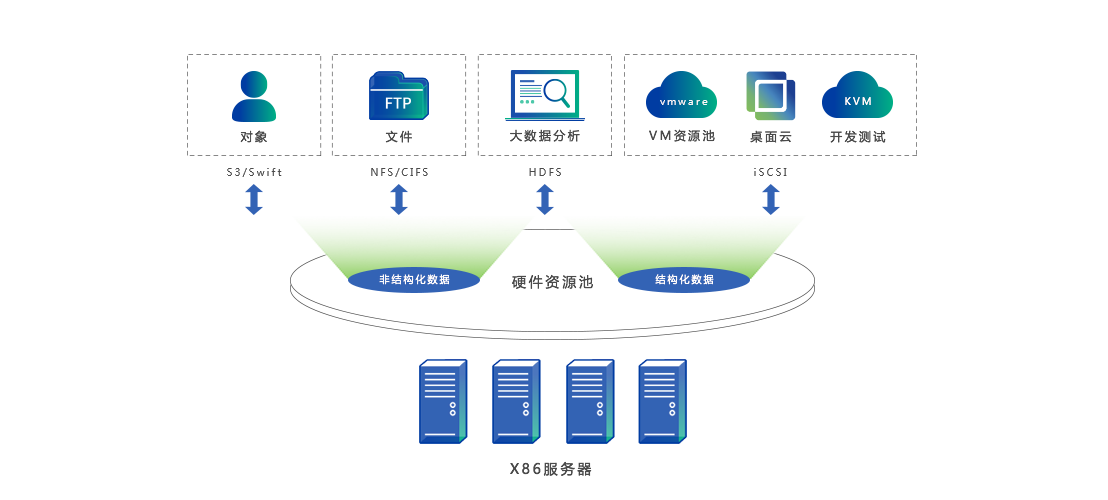
- 数据采集层:在各工厂部署边缘网关或代理,负责收集设备数据、生产事件等,支持多种协议(如OPC UA、MQTT)。数据经过预处理后,发送到中央平台。
- 数据处理层:采用分布式消息队列(如Kafka)作为数据总线,实现数据的缓冲和分发。处理引擎(如Flink或Spark Streaming)进行实时数据清洗、转换和聚合,生成业务指标。
- 数据存储层:根据数据类型选择存储方案:
- 实时数据:使用时序数据库(如InfluxDB或TimescaleDB),支持快速读写和查询。
- 历史数据:采用大数据存储(如HDFS或云对象存储),结合数据湖架构,便于长期分析和机器学习。
- 元数据与配置数据:使用关系型数据库(如PostgreSQL或MySQL),管理工厂、设备和用户信息。
- 服务与API层:提供RESTful API或GraphQL接口,供前端应用、报表工具和其他系统调用,实现数据共享和集成。
- 监控与运维层:集成日志、指标和告警系统(如Prometheus和Grafana),确保系统高可用性和性能优化。
四、实施策略与最佳实践
在具体实施过程中,建议采取以下策略:
- 分阶段部署:从试点工厂开始,验证架构可行性后逐步扩展,减少风险。
- 云原生与混合云:考虑使用云平台(如AWS、Azure或私有云)实现弹性伸缩,同时支持本地部署以满足数据本地化需求。
- 数据治理与质量管控:建立数据治理框架,包括数据字典、质量控制流程和备份策略,确保数据准确性和一致性。
- 培训与变更管理:为各工厂团队提供培训,促进系统 adoption,并设立支持机制应对运行问题。
- 持续优化:通过监控数据分析和用户反馈,不断优化处理性能和存储效率。
五、总结
构建集团企业多工厂MES的数据处理和存储服务是一项复杂但关键的任务。通过统一数据标准、采用分布式架构、结合实时与批处理技术,并注重安全与扩展性,企业可以实现高效、可靠的数据管理。这不仅提升了生产透明度和决策效率,还为未来智能制造转型奠定了基础。在实施过程中,分阶段推进和持续优化将确保系统成功落地,助力集团企业在竞争中保持领先。
如若转载,请注明出处:http://www.ghostplans.com/product/15.html
更新时间:2025-11-29 11:18:26